Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
Know More Before You Score: An
Analysis of Structure-Based Virtual
Screening Protocols
Structure-Based Virtual Screening (SBVS) is a proven
technique for lead discovery
Still many areas for improvement
Many efforts focussed on scoring function
Here we consider a number of these processes in detail from
the perspective of our primary SBVS tool (DOCK)
Often with little consideration of the assumptions underpinning SBVS
Ligand conformational search protocols
Varying site points definitions
Alteration of sampling variables
Determine their impact on hit enrichment and search speed
Analyze implications for future research
Ligand Flexibility Studies
Strategy
SBVS CPU intensive
Conformational searching of ligand clearly important
Sampling limited to allow search completion in reasonable time frame
Test required to compare different conformational
sampling methods
Ability to reproduce bioactive conformation tested
145 ligands from a 1995 analysis of pdb complexes (Gschwend
UCSF unpublished)
30 compound subset chosen for analysis- selection based on visual and
numerical inspection of diversity in ligand flexibility and functionality
Relatively small sample of molecules used, many peptidic in nature
Peptidic moieties are among the better parameterized systems, so
this is in some ways a best case scenario
Ligand Flexibility Studies
Procedure
Multiple sampling techniques chosen:
Catalyst-best / Catalyst-fast / Confort / Omega / DOCK
Variety of sampling levels
Starting from Concord structure, conformers generated
and superimposed onto pdb ligand conformation.
Conformation with lowest heavy atom RMS to used as quality
measure
Ligand Flexibility Studies
Search Settings Employed
Dock - conformation_cutoff_factor=3/5/10 clash_overlap=0.7 times
vdW radius for clash overlap with customized rules for bond increment
settings
Confort - Rough (0.10 kcal) convergence, diverse conformer selection,
boat ring search on - sampling at 5/10 confs per single bond + 500 max
Catalyst- Best/Fast Default settings - sampling at 5/10 confs per
single bond + 100 max
Omega: Defaults
sampling at 100 max
In addition Concord generated and Sybyl minimized ligand xray structures
also analyzed as “controls”
+ RMS_CUTOFF=1.0, GP_ENERGY_WINDOW=5.0,
1.76 1.80
14.00
12.00
10.00
8.00
6.00
4.00
2.00
0.00
Average internal rank
Average rms deviation
0.88 0.92 0.87
0.81
0.76
0.97 0.96 0.99 0.99 1.00 1.03
1.13
1.60
1.40
1.20
1.00
0.80
0.60
0.40
0.20
0.00
Average RMS deviation
Average internal rank
Ligand Flexibility Results
Overall Performance - RMS/ Rank
Ligand Flexibility Results
Performance vs Flexibility
2
3 to 5 single bonds (15)
6 to 8 single bonds (7)
9 to 14 single bonds (8)
1.5
1
0.5
n
C O xra y
NF
BE 5 00
ST
F A 10 0
ST
1
D O 00
CK
10
F
OM AS T
5
EG
A1
D O 00
CK
BE 5
ST
DO 5
CK
3
Co
nco
rd
0
Mi
Average RMS
Deviation
2.5
1.03
1.80
1.60
1.40
1.1251.20
1.00
0.80
0.60
0.40
0.20
0.00
DO
CK
3
0.97
DO
CK
5
FA
ST
5
0.96
DO
CK
10
00
BE
ST
1
00
0.81
0.92
0.88
CO
NF
10
0.87
FA
ST
10
0
100
90
80
70
60
50
40
30
20
10
0
Search Types
Does extra noise introduced to scoring functions outweigh this
improvement? Is it worth the extra CPU?
RMS deviation
Average conformations / molecule
Average rms deviation
425
CO
NF
5
Conformations / molecule
Ligand Flexibility Results
The Pain Gain Ratio
Ligand Flexibility Results
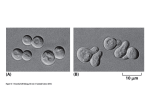
Visual Analysis
RMS=0.65
RMS=0.90
Even at lower RMS, deviation in hydrogen positions an issue
As RMS rises (0.9) we begin to see more significant deviations in
heavy atom positions - large enough to possibly prove troublesome to
standard force fields
Ligand Flexibility Results
Visual Analysis
RMS=1.55
RMS=2.19
As RMS rises further, hydrogen bond mapping begins to partially break
down
Significant deviation begins to be seen although general shape
complementarity is still reasonable
DOCKing tricky, pharmacophore searches possible with loose tolerances,
although site point vector definitions (DISCO / Catalyst) a no no
Ligand Flexibility
Conclusions
At current sampling levels used in virtual screening
Rough search techniques perform comparably to more exhaustive methods
Results highlight the need for “forgiving” scoring functions and
pharmacophore constraint tolerances (especially for flexible molecules)
Dock performs quite well, and Fast does slightly better than comparable Best run
Generating function directly from crystal structure data may not be optimum
Use the conformation closest to the biologically relevant structure with
chosen sampling technique
May be better to ignore more flexible molecules when possible (~>8 bonds)
Analysis of more extensive data set might provide basis for determining
if optimum sampling settings exist (Best/Omega/Confort)
Coarseness of poling values for example
Structure-Based Search Protocols
An Analysis of DOCK
Working within current DOCK paradigm, what search
protocols provide optimum search criterion?
Site point definitions
Alteration of sampling variables
Different scoring grids
Comparisons illustrated for 5 test systems with
diverse active data sets
Analysis based on ranking within list that includes
~10000 “noise” compounds
“Random” selection within bounds of size and flexibility
distribution seen in in-house database
Structure-Based Search Protocols
DOCK variables
Contains many variables that effect performance
Ligand sampling within the site being the primary variant
nodes
distance_tolerance
distance_minimum
bump_filter
conformation_cutoff_factor
clash_overlap
maximum_orientations
3/4
0.5/1.0
3.0
4
5
0.7
500/5000
Structure-Based Search Protocols
DOCK and pharmacophoric constraints
It is possible to assign fairly sophisticated pharmacophoric
(henceforth also known as chemical) definitions
Current types:
name acid
# deprotonated carboxyl
definition O.co2 ( C )
# tetrazole
definition N.pl3 ( H ) ( N.2 ( N.2 ( N.2 ( C.2 ) ) ) )
definition N.pl3 ( H ) ( N.2 ( N.2 ( C.2 ( N.2 ) ) ) )
definition N.2 ( N.2 ( N.2 ( C.2 ( N.pl3 ( H ) ) ) ) )
definition N.2 ( N.2 ( C.2 ( N.pl3 ( H ) ( N.2 ) ) ) )
definition N.2 ( C.2 ( N.2 ( N.pl3 ( H ) ( N.2 ) ) ) )
definition N.2 ( N.2 ( C.2 ( N.2 ( N.pl3 ( H ) ) ) ) )
definition N.2 ( N.pl3 ( H ) ( N.2 ( N.2 ( C.2 ) ) ) )
# acyl sulphonamide
definition N.am ( S ( 2 O.2 ) ) ( C.2 ( O.2 ) )
definition O.2 ( C.2 ( N.am ( H ) ( S ( 2 O.2 ) ) ) )
definition O.2 ( S ( O.2 ) ( N.am ( H ) ( C.2 ( O.2 ) ) )
heavy atom
donor
acceptor
hydrophobe
aromatic
aromatic_hydrophobic
acid
base
donor_and_acceptor
special (e.g. metal chelator)
Structure-Based Search Protocols
Site Points Used in Kinase Search
Region 1 ( + 4)
acceptor /
donor
Region 2
Hydrophobic +
2 donors
Region 3
Hydrophobic /
Any heavy atom
Structure-Based Search Protocols
Test Sets and Site Points Used
Sphgen used to generate site points for “generic” DOCK searches
Pharmacophore points derived from a mixture of non-data set bound ligands and
in-house programs that process GRID maps and Connolly surfaces (plus plenty
of human intervention)
Target
Active Chemotype
Definitions
Pharmacophore
Points / Critical
Regions
2 Serine
proteases
P1 substituent / P1P4 linker substituent
2 Fatty acid
binding
proteins
Kinase
Core linking acid
moiety to remaining
substituents
Moiety mimicing
adenine / main core
of molecules
P1 (base /
hydrophobe) + P4
(hydrophobe) pockets
Acid binding pocket
Adenine binding
pocket
(donor/acceptor) [+
rear hydrophobic
pocket]
Active data sets broken down into chemotypes to prevent the problem of
common analogue bias - an under appreciated issue in all validations
Results - kinase
Search type key: a_b_c(_d)
termination
.5
c_
43
cr_
1
cc
_f_
c_
43
cr_
1
.0
0
cc
_f_
c_
42
cr1
.
cc
_f_
.0
m_
1
c_
32
cri
t
cc
_f_
Chemotypes
Compounds
cc
_f_
cc
_f_
c_
1. 0
c_
3
cc
_f_
s_
f_m
10
8
6
4
2
0
Chemotypes
25
20
15
10
5
0
s_
f_c
Compounds
No. of hits after 50% of chemotypes located
by at least one search ( 400 compounds
processed from 96 actives / 18 chemotypes)
Search Type
e.g. cc_f_c_3 ***** NOTE poor 1 crit perform - premature
a: s=sphgen / c=critical / cc=chemical-critical
c: m=mm score / c = contact score
a.b distance tolerance
b: s=single conf / f=flexi dock
d: = nXcr(a.b) - n node search with X critical regions and
Results - fatty acid binding protein 2
No. of hits after 7 chemotypes located by at least one search ( 500
compounds processed from 28 actives / 8 chemotypes)
Search type key: a_b_c(_d)
s_
f_m
_e
sp
s_
f_c
_a
cid
c_
1.0
c_
3
cc
_f_
cc
_f_
c
cc
_f_
cc
_f_
Chemotypes
Compounds
m
0
c_
f_m
0
c_
f_c
2
s_
f_m
5
s_
f_c
4
s_
s_
m
10
Chemotypes
8
6
15
s_
s_
c
Compounds
Missing chemotype a citrazinate - not covered in chemical definitions easy to fix - another advantage over electrostatics
20
Search Types
e.g. cc_f_c_3
a: s=sphgen / c=critical / cc=chemical-critical
b: s=single conf / f=flexi dock
c: m=mm score / c = contact score d: 3=3 node search / 1.0=1.0 distance tolerance /
1.02crit/32crit = 1.0 distance tolerance or 3 node search with 2nd critical region ( hydrophobic
binding pocket) / esp = electrostatic potential included in mm score / acid=all non acids
removed from search lists
Results-Overall
Compounds processed for 50% Chemotype Coverage for All Systems
1400
Compounds
1200
1000
800
600
400
200
0
Best hit rate
Mean hit rate
Worst hit rate
Search Type
Search type key: a_b_c(_d) e.g. cc_f_c_3
a: s=sphgen / c=critical / cc=chemical-critical
c: m=mm score / c = contact score
b: s=single conf / f=flexi dock
d: 3=3 node search / 1.0=1.0 distance tolerance
Results Analysis:
DOCK Scoring Functions - Shape
Contact generally a little more robust than vdW non bonded
function
More controllable bump penalty (no rn repulsion)
Better able to deal with docking inaccuracies
More important in tight binding sites with pharmacophore constraints and flexible
molecules
controllable max. vdW repulsion value mitigates this somwhat
Still useful with less flexible molecules for a more rigorous shape complementarity
score
Results Analysis:
DOCK Scoring Functions - H Bonding
Electrostatics
Many intuitive reasons for caution in explicit treatment
Poor charge models / coarse conformations /inability to control ionization
states
Pharmacophore centers provides better vehicle for h bonding
description
Spread points to allow for search approximations / set critical regions
based on biological and structural information / faster searches (30-100
times)
Conclusions
For maximum impact impact current methodology, scoring functions should
either
Be designed/utilized with these limitations in mind
Forgiving / targeted at less flexible molecules
Improve results by such a high degree that additional sampling (and CPU) is
warranted
In the mean time, utility of pharmacophoric hypotheses {critical region(s)
with pharmacophoric constraints} is clear
Better results faster / less sensitivity to model coarseness / allows constraints
based on known biology
Acknowledgements
Thank
you to my BMS CADD colleagues