Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
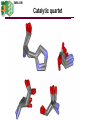
EMBL-EBI Visualization & Data mining EMBL-EBI Visualisation The process of representing abstract data to aid in understanding the meaning of the data. Not to be confused with rendering data (drawing pictures) Typically though, we render data in such a way to visualize the information within that data. EMBL-EBI Introduction Biological data comes from & is of interest to: Chemists : reaction mechanism, drug design Biologists : sequence, expression, homology, function. Structure biologists : atomic structure, fold, classification, function. Medicine : clinical effect Education : Media : Presentation of diverse information to a diverse audience. Each has there own point of view (context). Expert = scientist working within their own field of expertise Non-expert = scientist using data/information outside their field Novice = Non-scientist EMBL-EBI Not just presentation of results Web pages These are notoriously badly designed often resulting in the information on that site being unusable. The front page should load quickly The main point should appear on the first full screen Clutter – not logically laid out Too busy – cannot find the salient point 8% men & 0.5% women are colour blind Google is a Bad text/fonts Too often it doesn’t work good design User will go somewhere else The latest wiz-bang stuff only works on the latest browsers Only works in one browser – they only tested on one. – Does not conform to standard HTMl EMBL-EBI Asking questions Asking questions Biological data is very complex Chemistry, Biology, Physics, Statistics, Medicine.. Most users will be from a different field Asking the right question is difficult. The user cannot use the correct terminology Too many things to query (2000 attributes in MSD) SQL : not suitable for most users Interface too complex Too many check boxes, widgets etc Trying to be too clever The “Go” button is buried somewhere EMBL-EBI Result presentation Results Biological data is complex Chemistry, physics, biology, statistics, medicine… Experts users want all the detail Ie : want to use a specific method They want all the details The want (I hope) the statistical validity of the results The non-expert wants the best practice answer returned within their own context. The want comparative analysis with other fields The want to know the results are valid EMBL-EBI Query design The simple text box design is very common Suitable for text queries Only one logic AND or OR Predefined Easy to use Limited scope 2000 attributes -> 2000 check-boxes ! EMBL-EBI Query design Graphical interface Multiple logic AND/OR/NOT Under users control Slower Steep learning curve Some users just cannot get it Intuitive once mastered Pretty EMBL-EBI Query design Figurative 2D sketch for 3D query (Active sites) Informative – presents meaning for the question Slower Less error prone HIS|SER:S/H>C2.0 HIS.ne2:S/S>C2.0 HIS.[n]/T>C2.0 EMBL-EBI YAMGP (yet another molecular graphics program) Many different programs are available AstexViewer@MSD-EBI LigPlot VMD Quanta InsightII Bobscript WebMol Frodo iMol Chime Grasp Pymol POVRay Spock Rasmol Pymol Mage Raster3D Yasara Molscript Chimera O MolMol Whatif Frodo XtalView WebLab-viewer Swiss-PDBviewer EMBL-EBI Result visualisation Multiple types of biological data Textual data 3D structure 2D chemical sketches 1D sequence Node linked General/derived data Web pages Time Errors/Variance Patented ! EMBL-EBI Visualisation : AstexViewer@MSI-EBI Visualisation Structure/sequence/data Lensing Linked views Brushing Picking Flying views Hyperbolic distortion Animation Solid rendering Depth cues Colour,lighting Highlighting Etc… EMBL-EBI Visualisation : comparative analysis Similarity/Difference Data superposition Attribute display Colour, size… Correlation Attribute mapping Sequence colour by structure alignment Analysis Example EMBL-EBI Animation Animation Time dependent display Reaction chemistry Visual clues. Expression data Shown as… Rotation Flash On/off Object Synchronization Size, Colour…. Sound NO : incredibly annoying Animation Example EMBL-EBI Multidimensional analysis Comparative analysis on multiple data Eg. Phi,Psi, Bvalue, Omega 1D & 2D easy 3D graphs are difficult to see. 4D requires 3D + iso-surfaces Higher – too busy Use 2D + multiple properties SPOTFIRE is the most well known Use : X/Y/Colour/size/shape… Interactive bracketing Example EMBL-EBI Visualization- Summary Rendering data is not visualization Not just the display of results Huge array of non-specific techniques – and entire scientific field ! EMBL-EBI Data mining “Analysis of data in a database using tools which look for trends or anomalies without knowledge of the meaning of the data.” (Hyperdictionary) “True data mining software does not just change the presentation, but discovers previously unknown relationships among the data.” (IBM) EMBL-EBI Data mining & Data analysis Traditional analysis is via “verification-driven analysis” Requires hypothesis of the desired information (target) Requires correct interpretation of proposed query Discovery-driven data mining Finds data with common characteristics Results are ideal solutions to discovery Finds results without previous hypothesis Results have unbiased mean and variance EMBL-EBI So what is Hypothesis driven data analysis ? Define a target = hypothesis Search for target There are/are-not “hits” Verify/negate hypothesis Distribution is centred on target “catalytic triad” : Atomic coordinates : Mathematical graph : HIS,ASP,SER : text string matching coordinate superposition graph matching data hierarchy knowledge EMBL-EBI Four types of data mining Creation of predictive models : future data expectation Link analysis : connections between data objects Database segmentation : classification Deviation detection : finding outliers. IBM : white papers EMBL-EBI So what is this data mining ? Given multiple sets of primary data (dependant variables) Characters, numbers, Function(numbers),…. Find anomalies To many : numerical occurrence Data variation : Derivatives Singularities ….. Correlations and clusters Within primary data with other data (independent variables) Finds new things ! But not what it means ! EMBL-EBI Eg Retail and Financial industry are heavily into DM. A well known US food supermarket chain found a correlation : Babies nappies Beer 5pm on Friday Wife rings husband, “get some nappies for the weekend” Husband takes opportunity to buy some beer ! You won’t grant funding to test this hypothesis ! EMBL-EBI Self/Cross data mining Most mining software looks for correlations between dependent variables. Rainfall, temperature, cloud-cover It rains when it is cloudy Free : http://www.cs.waikato.ac.nz/~ml/ Bioinformatics usually involves anomalies within data objects Sequence clusters (sequence finger prints) Local coordinate clusters (active sites) Global coordinate cluster (folds) EMBL-EBI Data mining – not idiot proof Date of birth and age will give 100 % correlation Authors for structure submission will be correlated to authors on primary citation. “Lysozyme” is the most common fold pattern 36 spelling’s of E.Coli will mask results. Requires representative sets Statistically valid ones too ! Signal/Noise ratio is a problem EMBL-EBI Discovery driven data mining of the PDB Analysis of 3-dimensional coordinates Defined common patterns of atomic interactions locally DB segmentation - active sites & common packing features Link analysis - Similarity between different functional group Defined globally DB segmentation - common patterns of super-secondary str’ Link analysis - common folds in diverse protein families Outlier detection - unique folds EMBL-EBI Issues Systematic “error” propagates as solution 300 lysozyme structures return as a strong solution Results cannot be found below the noise level Need to characterise the noise level Need to improve signal/noise ratio (S/N) to see information Target is not biologically defined It does not give you the biological answer Results should reproduce known biology Can give you new results not previously observed EMBL-EBI Data selection Cannot leave in 300 lysozyme structures ! Select by sequence similarity at 70% exact alignment Different “phase space” to select data Remove structures with resolution < 2.5A Remove NMR (different statistics) Remove pre-1982 etc. Geometrical analysis criteria to check for outliers Using properties NOT target parameters of structure solution EMBL-EBI Local atomic interactions Data Function(3D coordinates) = distance Atom names (independent variable) Residue names (independent variable) Create 3D Hash table of triplets of distances(*) between “points” This is the dependant variable Order = 3 EMBL-EBI Local atomic interactions Merge triplets Any pair of N-fold interactions are a (N+1) interaction if they have (N-1) equivalence. Order = N Just keep going until no more (N+1) interaction are found. Time = 8 seconds to find ~ 2000 interactions (Digital alpha ES40) EMBL-EBI Catalytic quartet EMBL-EBI Electrostatic interaction Ligands are found close by rather than associated with the residues EMBL-EBI Iron binding site EMBL-EBI Double disulphide EMBL-EBI N-linked glycosolation binding site + Spot the non-sugar This glycosolation site is the same as active site found in “1a53” – indol-3glycerolphosphate synthase EMBL-EBI Summary Nearly all Bioinformatics is based on hypothesis driven data analysis Data mining has lost its meaning within Bioinformatics. Discovery driven data-analysis (true data mining) : Can find unknown dependencies, clusters, outliers Is based on statistical probability Returns distributions unbiased by previous ideas Information technology may be better for genomes (1D) “A numerical measure of the uncertainty of an outcome” Information content of gene sequences can be defined by the normalized probability of finding “words” within that sequence