Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
CSE 881: Data Mining
Lecture 22: Anomaly Detection
‹#›
Anomaly/Outlier Detection
What are anomalies/outliers?
– Data points whose characteristics are considerably
different than the remainder of the data
Applications:
–
–
–
–
Credit card fraud detection
telecommunication fraud detection
network intrusion detection
fault detection
‹#›
Examples of Anomalies
Data from different classes
– An object may be different from other objects because
it is of a different type or class
Natural (random) variation in data
– Many data sets can be modeled by statistical
distributions (e.g., Gaussian distribution)
– Probability of an object decreases rapidly as its
distance from the center of the distribution increases
– Chebyshev inequality:
2
P(| X | c)
c2
Data measurement or collection errors
‹#›
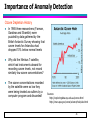
Importance of Anomaly Detection
Ozone Depletion History
In 1985 three researchers (Farman,
Gardinar and Shanklin) were
puzzled by data gathered by the
British Antarctic Survey showing that
ozone levels for Antarctica had
dropped 10% below normal levels
Why did the Nimbus 7 satellite,
which had instruments aboard for
recording ozone levels, not record
similarly low ozone concentrations?
The ozone concentrations recorded
by the satellite were so low they
were being treated as outliers by a
computer program and discarded!
Sources:
http://exploringdata.cqu.edu.au/ozone.html
http://www.epa.gov/ozone/science/hole/size.html
‹#›
Anomalies
General characteristics
– Rare occurrence
– Deviant behavior compared to
the majority of the data
Distribution
– Natural variation
uniform distribution
– Data from different classes
distribution may be clustered
‹#›
Anomaly Detection
Challenges
– Method is (mostly) unsupervised
Validation can be quite challenging (just like for clustering)
– Small number of anomalies
Finding needle in a haystack
‹#›
Anomaly Detection Schemes
General Steps
– Build a profile of the “normal” behavior
Profile can be patterns or summary statistics for the normal population
– Use the “normal” profile to detect anomalies
Anomalies are observations whose characteristics
differ significantly from the normal profile
Types of anomaly detection
schemes
– Graphical & Statistical-based
– Distance-based
‹#›
Graphical Approaches
Boxplot (1-D), Scatter plot (2-D), Spin plot (3-D)
Limitations
– Time consuming
– Subjective
‹#›
Convex Hull Method
Extreme points are assumed to be outliers
Use convex hull method to detect extreme values
What if the outlier occurs in the middle of the
data?
‹#›
Statistical Approaches
Assume a parametric model describing the
distribution of the data (e.g., normal distribution)
Apply a statistical test that depends on
– Data distribution
– Parameter of distribution (e.g., mean, variance)
– Number of expected outliers (confidence limit)
‹#›
Grubbs’ Test
Detect outliers in univariate data
Assume data comes from normal distribution
Detects one outlier at a time, remove the outlier,
and repeat
– H0: There is no outlier in data
– HA: There is at least one outlier
Grubbs’ test statistic:
Reject H0 if:
( N 1)
G
N
G
max X X
s
t (2 / N , N 2 )
N 2 t (2 / N , N 2 )
‹#›
Statistical-based – Likelihood Approach
Assume the data set D consists of samples from
a mixture of two probability distributions:
– M (majority distribution)
– A (anomalous distribution)
General Approach:
– Initially, assume all the data points belong to M
– Let Lt(D) be the log likelihood of D
– Choose a point xt that belongs to M and move it to A
Let Lt+1 (D) be the new log likelihood.
Compute the difference, = Lt(D) – Lt+1 (D)
If > c (some threshold), then xt is declared an anomaly and
is moved permanently from M to A
‹#›
Statistical-based – Likelihood Approach
Data distribution, D = (1 – ) M + A
– M is a probability distribution estimated from data
Can
be based on any modeling method (naïve Bayes,
maximum entropy, etc)
– A is often assumed to be uniform distribution
Likelihood at time t:
|At |
|M t |
Lt ( D ) PD ( xi ) (1 ) PM t ( xi ) PAt ( xi )
i 1
xi M t
xiAt
LLt ( D ) M t log( 1 ) log PM t ( xi ) At log log PAt ( xi )
N
xi M t
xi At
‹#›
Limitations of Statistical Approaches
Most of the tests are for a single attribute
In many cases, the data distribution may not be
known
For high dimensional data, it may be difficult to
estimate the true distribution
‹#›
Distance-based Approaches
Data is represented as a vector of features
Three approaches
– Nearest-neighbor based
– Density based
– Clustering based
‹#›
Nearest-Neighbor Based Approach
Approach:
– Compute the distance between every pair of data
points
– There are various ways to define outliers:
Data
points with fewer than p points within a neighborhood of
radius D
Data
points whose distance to the kth nearest neighbor is
among the highest
Data
points whose average distance to the k nearest
neighbors is among the highest
‹#›
Outliers in Lower Dimensional Projection
Divide each attribute into equal-depth intervals
– Each interval contains a fraction f = 1/ of the records
Consider a k-dimensional cube created by
picking grid ranges from k different dimensions
– If attributes are independent, we expect region to
contain a fraction fk of the records
– If there are N points, we can measure sparsity of a
cube D as:
– Negative sparsity indicates cube contains smaller
number of points than expected
‹#›
Example
N=100, = 5, f = 1/5 = 0.2, N f2 = 4
‹#›
Density-based: LOF approach
For each point, compute the density of its local
neighborhood
Compute local outlier factor (LOF) of a sample p as the
average of the ratios of the density of sample p and the
density of its nearest neighbors
Outliers are points with largest LOF value
In the NN approach, p2 is
not considered as outlier,
while LOF approach find
both p1 and p2 as outliers
p2
p1
‹#›
Clustering-Based
Basic idea:
– Cluster the data into
groups of different density
– Choose points in small
cluster as candidate
outliers
– Compute the distance
between candidate points
and non-candidate
clusters.
If
candidate points are far
from all other non-candidate
points, they are outliers
‹#›
One-Class SVM
Based on support vector clustering
– Extension of SVM approach to clustering
– 2 key ideas in SVM:
It uses the maximal margin principle to find the linear
separating hyperplane
For nonlinearly separable data, it uses a kernel function to
project the data into higher dimensional space
‹#›
Support Vector Machine (Idea 1)
Maximal margin principle
2
Margin
|| w ||
Objective function to minimize:
2
|| w ||
N k
L( w)
C i
2
i 1
subject to the following constraints:
if w x i b 1 - i
1
yi
1 if w x i b 1 i
wx b 0
‹#›
Support Vector Machine (Idea 2)
Original Space
High-dimensional Feature Space
‹#›
Support Vector Clustering
What is the corresponding
maximum margin
principle?
?
Original Space
High-dimensional Feature Space
‹#›
Support Vector Clustering
In SVM
– Start with the simplest case first, then make the
problem more complex
– Simplest case: linearly separable data
Apply same idea to clustering
– What is the simplest case?
All the points belong to a single cluster
The cluster is globular (spherical)
‹#›
Support Vector Clustering
B2
SVM
Choose the hyperplane with
largest margin
SVC
Choose the sphere with
smallest radius
‹#›
Support Vector Clustering
Let R be the radius of the sphere
Goal is to:
min R 2
R
subject to:
a
i : xi a R 2
2
x
where:
– a is the center of the sphere
‹#›
Support Vector Clustering
Objective function: min R i R xi a
2
R , a ,{ }
2
i
– where I’s are the Lagrange multipliers
– Subject to:
i 0
i : i R xi a
2
2
0
(KKT condition)
L
2 R 2R i 0 i 1
R
i
i
L
2 i ( xi a) 0 i xi a
a
i
i
‹#›
2
Support Vector Clustering
Objective function (dual form):
LR
2
R
2
i
xi a
2
i
2
R 2 i R 2 i xi j x j
i
i
j
2
R R i xi 2 j xi x j j k x j xk
i
j
j ,k
2
2
i xi i j xi x j
2
i
i
j
Find the I’s that maximizes the expression s.t.
i : i R 2 xi a
2
0
(KKT condition)
‹#›
Support Vector Clustering
Since i : i R xi a
2
2
0
– If xi is located in the interior of the sphere, then i = 0
– If xi is located on the surface of the sphere then i 0
Support vectors are the data points located on
the cluster boundary
‹#›
Outliers
Outliers are considered data points located
outside the sphere
Let i be the error for xi
Goal is to:
min R 2 C i
R ,{ }
a
i
– subject to:
i : xi a R 2 i , i 0
2
‹#›
x
Outliers
Lagrangian:
min
R C i i R i xi a
2
R , a ,{ },{ }
i
i
– Subject to:
i : R
i
2
xi a
2
2
2
i i
i
0, 0
i i
(KKT conditions )
L
2R 2R i 0 i 1
R
i
i
L
2 i ( xi a ) 0 i xi a
a
i
i
L
C i i 0 i C i
i
‹#›
Outliers
Dual form:
L R C i i R i xi a
2
i
2
i
2
i i
i
R 2 ( i i ) i i R 2 i xi i x j
i
i
j
2
i i
i
2
i xi i x j
i
j
i xi i j xi x j
2
i
i
j
– Same as the previous (no outlier) case
‹#›
Outliers
Since i : i R xi a
2
2
0, 0
i i
– If xi is located in the interior of the sphere, then i = 0
– If xi is located on the surface of the sphere then i 0
Such points are called the support vectors
– If xi is located outside of the sphere then i = 0
Such points are called the bounded support vectors
‹#›
Irregular Shaped Clusters
What if the cluster have irregular shaped in the
original space?
– Instead of using a very large sphere, or a sphere with
large errors ( i), project the data into higherdimensional space (kernel trick)
(xi)
xi
‹#›
Irregular Shaped Clusters
Objective function (dual form):
( x ) ( x ) ( x ) ( x )
i
i
i
i
i
i
j
i
j
j
Kernel trick:
– Use kernel function in place of (xi) (xj)
– Typical kernel function:
Gaussian:
K ( xi , x j ) e
q xi x j
2
‹#›
References
Support Vector Clustering
By Ben-Hur, Horn, Siegelmann, and Vapnik
(Journal of Machine Learning Research, 2001)
http://citeseer.ist.psu.edu/hur01support.html
Cone Cluster Labeling for Support Vector
Clustering
By Lee and Daniels
(in Proc. of SIAM Int’l Conf on Data Mining, 2006)
http://www.siam.org/meetings/sdm06/proceedings/046lees.pdf
‹#›
Graph-based Method
Represent the data as a graph
– Objects nodes
– Similarity edges
Objects
Object Graph
Apply graph-based method to determine outliers
‹#›
Graph-based Method
Find the most outlying node in the graph
=> Opposite of finding the most “central” node
‹#›
Graph-based Method
Many measures of node centrality
– Degree
– Closeness: c(n)
uV
1
d (u, n)
where d(u,n) is the geodesic distance between u and n
– Geodesic distance is the shortest path distance
– Betweenness: c(n)
j k
g jk (n)
g jk
where gjk(n) is the number of geodesic paths from j to k that
pass through n
– Random walk method
‹#›
Random Walk Method
Random walk model
– Randomly pick a starting node, s
– Randomly choose a neighboring node linked to s. Set
current node s to be the neighboring node.
– Repeat step 2
Compute the probability that you will reach a
particular node in the graph
– The higher the probability, the more “central” the node
is.
‹#›
Random Walk Method
Goal: Find the stationary distribution c
– Vector c represents probability value for each object
– Initially, set c(i) = 1/N (for all i=1,…,N)
Let S be the adjacency matrix of the graph
– Normalized the rows so that S(i,j) becomes a
transition probability
Iteratively compute:
cS c
T
– Until c converges to a stationary distribution
– To ensure convergence, use a damping factor, d:
c d (1 d )S c
T
‹#›
Random Walk Method
Applications
– Web search (PageRank algorithm used by Google)
– Text summarization
– Keyword extraction
‹#›
Random Walk for Anomaly Detection
Assess the centrality or importance of individual
objects
Highly relevant
web pages
Anomalies
For closely related data (e.g.,
documents returned by PageRank)
For data containing anomalies
‹#›
Example
Sample dataset
6
5
4
3
2
O1
1
O2
0
0
1
2
3
4
5
Model parameter tuning
– damping factor=0.1
– Converge after 112 steps
Object
1
2
3
4
5
6
7
8
9
10
11
Connectivity
0.0835
0.0764
0.0930
0.0922
0.0914
0.0940
0.0936
0.0930
0.0942
0.0942
0.0939
Rank
2
1
5
4
3
9
7
6
10
11
8
‹#›