Survey
* Your assessment is very important for improving the workof artificial intelligence, which forms the content of this project
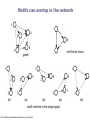
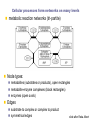
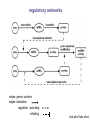
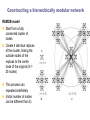
School of Information University of Michigan SI 614 Network subgraphs (motifs) Biological networks Lecture 11 Instructor: Lada Adamic Outline motifs motif detection (software & Pajek) review of network characteristics used to compare model with real-world network one more: degree assortativity biological networks types characteristics hierarchical modularity model Schematic view of network motif detection Motifs can overlap in the network graph motif matches in the target graph http://mavisto.ipk-gatersleben.de/frequency_concepts.html motif to be found Examples of network motifs (3 nodes) Feed forward loop Found in neural networks Seems to be used to neutralize “biological noise” Single-Input Module e.g. gene control networks All 3 node motifs Examples of network motifs (4 nodes) Parallel paths W Found in neural networks Food webs X Y Z 4 node subgraphs (computational expense increases with the size of the graph!) Network motif detection Some motifs will occur more often in real world networks than random networks Technique: construct many random graphs with the same number of nodes and edges (same node degree distribution?) count the number of motifs in those graphs calculate the Z score: the probability that the given number of motifs in the real world network could have occurred by chance Software available: http://www.weizmann.ac.il/mcb/UriAlon/ What the Z score means m = mean number of times the motif appeared in the random graph s standard deviation the probability observing a Z score of 2 is 0.02275 In the context of motifs: Z > 0, motif occurs more often than for random graphs Z < 0, motif occurs less often than in random graphs # of times motif appeared in random graph zx = x - mx sx |Z| > 1.65, only a 5% chance of random occurence Finding classes on graphs based on their motif “profiles” Finding motifs (cliques and subgraphs) in Pajek Create a second network that is the subgraph you are looking for e.g. an undirected triad *Vertices 3 1 "v1" 2 "v2" 3 "v3" *Arcs *Edges 2 3 1 1 2 1 1 3 1 finding motifs with Pajek Use the two drop down menus in the ‘networks’ list to specify two networks: Then run Nets>Fragment (1 in 2)>Find under Net>Fragment (1 in 2)>Options can select ‘induced’ subnetwork containing only overlapping fragments in finding motifs with Pajek (cont’d) Now we have just the triads: Creates a hierarchy object with the membership of each triad listed Comparing network models with the real thing check for structural similarity between the artificial network (the model) and the real world network degree distribution assortativity do high degree nodes connect to other high degree nodes? average shortest path dependence on size of network clustering coefficient compare to a randomized version conserving node degree dependence on node degree dependence on size of network motif profile How can we randomize a network while preserving the degree distribution? Stub reconnection algorithm (M. E. Newman, et al, 2001, also known in mathematical literature since 1960s) Break every edge in two “edge stubs” AB to A B Randomly reconnect stubs Problems: Leads to multiple edges Cannot be modified to preserve additional topological properties Local rewiring algorithm Randomly select and rewire two edges (Maslov, Sneppen, 2002, also known in mathematical literature since 1960s) Repeat many times Preserves both the number of upstream and downstream neighbors of each node Conserving additional low-level topological properties In addition to ki one may also conserve: The exact numbers of loops or other motifs The size and numbers of components: Internet – all nodes have to be connected to each other Metropolis algorithm: two edges are rewired based on E=(Nactual-Ndesired)2/Ndesired If E0 rewiring step is always accepted If E>0 rewiring step is accepted with p=exp(-E/T) Assortativity Social networks are assortative: the gregarious people associate with other gregarious people the loners associate with other loners The Internet is disassortative: Assortative: hubs connect to hubs Random Disassortative: hubs are in the periphery Correlation profile of a network Detects preferences in linking of nodes to each other based on their connectivity Measure N(k0,k1) – the number of edges between nodes with connectivities k0 and k1 Compare it to Nr(k0,k1) – the same property in a properly randomized network Very noise-tolerant with respect to both false positives and negatives Correlation profiles give complex networks unique identities 2D picture Protein interactions slide by Sergei Maslov Internet Correlation profiles give complex networks unique identities Sergei Maslov: 2D histogram Protein interactions Internet Correlation profiles -cont’d Pastor-Satorras and Vespignani: 2D plot average degree of the node’s neighbors degree of node Correlation profiles -cont’d Newman: single number -0.189 internet degree correlation coefficient The Pearson correlation coefficient of nodes on each side on an edge Other examples of assortative mixing Assortativity is not limited to degree-degree correlations other attributes social networks: race, income, gender, age food webs: herbivores, carnivores internet: high level connectivity providers, ISPs, consumers Tendency of like individuals to associate: ‘homophily’ Scott Feld paper Biological networks In biological systems nodes and edges can represent different things nodes protein, gene, chemical edges mass transfer, regulation Can construct bipartite or tripartite networks: e.g. genes and proteins GENOME protein-gene interactions PROTEOME protein-protein interactions METABOLISM bio-chemical reactions slide after Reka Albert Cellular processes form networks on many levels metabolic reaction networks (tri-partite) Node types: metabolites (substrates or products), open rectangles metabolite-enzyme complexes (black rectangles) enzymes (open ovals) Edges substrate to complex or complex to product symmetrical edges slide after Reka Albert regulatory networks nodes: genes, proteins edges: translation regulation: activating inhibiting slide after Reka Albert the yeast two-hybrid method Activation and binding domains are separated and each attached to a different protein If the proteins interact, the two domains will be brought together and activate the transcription of a reporter gene Can do simultaneous genome-wide experiments slide after Reka Albert Resulting interaction network slide after Reka Albert Properties and problems of resulting networks Properties giant component exists power law distribution with an exponential cutoff longer path length than randomized higher incidence of short loops than randomized Problems false positives false negatives only 20% overlap between different studies Implications Robustness resilient to random breakdowns mutations in hubs can be deadly Evolution most connected hubs conserved across organisms (important) gene duplication hypothesis new gene still has same output protein, but no selection pressure because the original gene is still present. So some interactions can be added or dropped leads to scale free topology Metabolic networks: how to represent them Can consider the one-mode projection of substrate interactions (undirected) slide after Reka Albert Metabolic networks are scale-free In the bi-partite graph: the probability that a given substrate participates in k reactions is k-a indegree: a = 2.2 outdegree: a = 2.2 (a) A. fulgidus (Archae) (b) E. coli (Bacterium) (c) C. elegans (Eukaryote), (d) averaged over 43 organisms Modularity No modularity Modularity Hierarchical modularity E. Ravasz et al., Science 297, 1551 -1555 (2002) (Pajek!) How do we know that metabolic networks are modular? clustering decreases with degree as C(k)~ k-1 randomized networks (which preserve the power law degree distribution) have a clustering coefficient independent of degree How do we know that metabolic networks are modular? clustering coefficient is the same across metabolic networks in different species with the same substrate corresponding randomized scale free network: C(N) ~ N-0.75 (simulation, no analytical result) bacteria archaea (extreme-environment single cell organisms) eukaryotes (plants, animals, fungi, protists) scale free network of the same size review: what would the clustering coefficient of a random network be assume average degree of node is k probability of one neighbor linking to another is ~ k/N scales as N-1 Constructing a hierarchically modular network RSMOB model Start from a fully connected cluster of nodes Create 4 identical replicas of the cluster, linking the outside nodes of the replicas to the center node of the original (N = 25 nodes) This process can repeated indefinitely (initial number of nodes can be different than 5) Properties of the hierarchically modular model RSMOB model Power law exponent g = 2.26 (in agreement with real world metabolic networks) C ≈ 0.6, independent of network size (also comparable with observed real-world values) C(k) ≈ k-1, as in real world network How to test for hierarchically arranged modules in real world networks perform hierarchical clustering on the topological overlap map (we’ll cover hierarchical clustering in a few weeks…) can be done with Pajek Topological overlap A: Network consisting of nested modules B: Topological overlap matrix hierarchical clustering Hubs may act within a module, or connect modules Party hub: simultaneous interactions tends to be within the same module Date hub: sequential interactions connect different modules Han et al, Nature 443, 88 (2004) slide after Reka Albert some matching motifs frequently overlap (e.g. feed forward loop) Zhang et al, J. Biol 4, 6 (2005)