Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
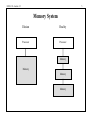
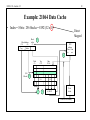
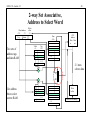
ENGS 116 Lecture 12 1 Caches Vincent H. Berk Wednesday October 29th, 2008 Reading for Friday: Sections C.1 – C.3 Article for Friday: Jouppi Reading for Monday: Section C.4 – C.7 ENGS 116 Lecture 12 2 Who Cares about the Memory Hierarchy? • So far, have discussed only processor – CPU Cost/Performance, ISA, Pipelined Execution, ILP 1000 CPU CPU-DRAM Gap 100 10 DRAM • • • 1980: no cache in microprocessors 1995: 2-level cache, 60% transistors on Alpha 21164 2002: IBM experimenting with Main Memory on die. 2000 1999 1998 1997 1996 1995 1994 1993 1992 1991 1990 1989 1988 1987 1986 1985 1984 1983 1982 1981 1980 1 ENGS 116 Lecture 12 3 The Motivation for Caches Memory System Processor Cache Main Memory • Motivation: – Large memories (DRAM) are slow – Small memories (SRAM) are fast • Make the average access time small by servicing most accesses from a small, fast memory • Reduce the bandwidth required of the large memory ENGS 116 Lecture 12 Principle of Locality of Reference • Programs do not access their data or code all at once or with equal probability – Rule of thumb: Program spends 90% of its execution time in only 10% of the code • Programs access a small portion of the address space at any one time • Programs tend to reuse data and instructions that they have recently used • Implication of locality: Can predict with reasonable accuracy what instructions and data a program will use in the near future based on its accesses in the recent past 4 ENGS 116 Lecture 12 5 Memory System Illusion Reality Processor Processor Memory Memory Memory Memory ENGS 116 Lecture 12 6 General Principles • Locality – Temporal Locality: referenced again soon – Spatial Locality: nearby items referenced soon • Locality + smaller HW is faster memory hierarchy – Levels: each smaller, faster, more expensive/byte than level below – Inclusive: data found in top also found in lower levels • Definitions – Upper is closer to processor – Block: minimum, address aligned unit that fits in cache – Address = Block frame address + block offset address – Hit time: time to access upper level, including hit determination ENGS 116 Lecture 12 7 Cache Measures • Hit rate: fraction of accesses found in that level – So high that we usually talk about the miss rate – Miss rate fallacy: miss rate induces miss penalty, determines average memory performance • Average memory-access time (AMAT) = Hit time + Miss rate x Miss penalty (ns or clocks) • Miss penalty: time to replace a block from lower level, including time to copy to and restart CPU – – access time: time to lower level = ƒ(lower level latency) transfer time: time to transfer block = ƒ(BW upper & lower, block size) ENGS 116 Lecture 12 8 Block Size vs. Cache Measures • Increasing block size generally increases the miss penalty Miss Penalty Miss penalty Transfer time Miss Rate Miss rate Avg. Memory Access Time => Average access time Access time Block Size Block Size Block Size ENGS 116 Lecture 12 Key Points of Memory Hierarchy • Need methods to give illusion of large, fast memory • Programs exhibit both temporal locality and spatial locality – Keep more recently accessed data closer to the processor – Keep multiple contiguous words together in memory blocks • Use smaller, faster memory close to processor – hits are processed quickly; misses require access to larger, slower memory • If hit rate is high, memory hierarchy has access time close to that of highest (fastest) level and size equal to that of lowest (largest) level 9 ENGS 116 Lecture 12 10 Implications for CPU • Fast hit check since every memory access needs this check – Hit is the common case • Unpredictable memory access time – 10s of clock cycles: wait – 1000s of clock cycles: (Operating System) » Interrupt & switch & do something else » Lightweight: multithreaded execution ENGS 116 Lecture 12 Four Memory Hierarchy Questions • Q1: Where can a block be placed in the upper level? (Block placement) • Q2: How is a block found if it is in the upper level? (Block identification) • Q3: Which block should be replaced on a miss? (Block replacement) • Q4: What happens on a write? (Write strategy) 11 ENGS 116 Lecture 12 12 Q1: Where can a block be placed in the cache? • Block 12 placed in 8 block cache: – Fully associative, direct mapped, 2-way set associative – S.A. Mapping = Block number modulo number sets Fully associative: block 12 can go anywhere Block no. 0 1 2 3 4 5 6 7 Direct mapped: block 12 can go only into block 4 (12 mod 8) Block no. 0 1 2 3 4 5 6 7 Set associative: block 12 can go anywhere in set 0 (12 mod 4) Block no. 0 1 2 3 4 5 6 7 Cache Set Set Set Set 0 1 2 3 Block frame address Block no. Memory 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 ENGS 116 Lecture 12 13 Direct Mapped Cache • Each memory location is mapped to exactly one location in the cache • Cache location assigned based on address of word in memory • Mapping: (address of block) mod (# of blocks in cache) 000 00000 00100 01000 001 010 01100 011 100 101 10000 110 111 10100 11000 11100 ENGS 116 Lecture 12 14 Associative Caches • Fully Associative: block can go anywhere in the cache • N-way Set Associative: block can go in one of N locations in the set ENGS 116 Lecture 12 15 Q2: How is a block found if it is in the cache? • Tag on each block – No need to check index or block offset • Increasing associativity shrinks index, expands tag Block Address Tag Index Fully Associative: No index Direct Mapped: Large index Block Offset ENGS 116 Lecture 12 16 Examples • 512-byte cache, 4-way set associative, 16-byte blocks, byte addressable • 8-KB cache, 2-way set associative, 32-byte blocks, byte addressable ENGS 116 Lecture 12 17 Q3: Which block should be replaced on a miss? • Easy for direct mapped • Set associative or fully associative: – Random (large associativities) – LRU (smaller associativities) – FIFO (large associativities) Associativity: 2-way Size LRU Random 16 KB 114.1 117.3 64 KB 103.4 104.3 256 KB 92.2 92.1 FIFO 115.5 103.9 92.5 4-way LRU Random 111.7 115.1 102.4 102.3 92.1 92.1 FIFO 113.3 103.1 92.5 ENGS 116 Lecture 12 18 Q4: What Happens on a Write? • Write through: The information is written to both the block in the cache and to the block in the lower-level memory. • Write back: The information is written only to the block in the cache. The modified cache block is written to main memory only when it is replaced. – Is block clean or dirty? • Pros and Cons of each: – WT: read misses cannot result in writes (because of replacements) – WB: no writes of repeated writes • WT always combined with write buffers so that we don’t wait for lower level memory • WB write buffer, giving a read-miss precedence ENGS 116 Lecture 12 19 Example: 21064 Data Cache • Index = 8 bits: 256 blocks = 8192/(32 x 1) Block offset <5> Block address <21> <8> Tag Direct Mapped 1 CPU address Data Data in out Index 4 Valid <1> (256 Blocks) Tag <21> Data <256> 2 ••• =? ••• 3 4:1 MUX Write buffer Lower Level Memory ENGS 116 Lecture 12 20 2-way Set Associative, Address to Select Word Block address <22> <7> Tag Two sets of address tags and data RAM Block offset <5> CPU address Data Data in out Data <64> Index Valid <1> Tag <21> ••• ••• 2:1 mux selects data =? 2:1 MU X =? Use address bits to select correct RAM Write buffer ••• ••• Lower Level Memory ENGS 116 Lecture 12 21 Structural Hazard: Instruction and Data? Size Instruction Cache 8 KB 8.16 16 KB 3.82 32 KB 1.36 64 KB 0.61 128 KB 0.30 256 KB 0.02 Misses per 1000 instructions Mix: instructions 74%, data 26% Data Cache 44.0 40.9 38.4 36.9 35.3 32.6 Unified Cache 63.0 51.0 43.3 39.4 36.2 32.9 ENGS 116 Lecture 12 22 Cache Performance includes hit time CPU time = (CPU execution clock cycles + Memory-stall clock cycles) Clock cycle time Memory-stall clock cycles = = = Read-stall cycles + Write-stall cycles Memory access Miss rate Miss penalty Program Instructio ns Misses Miss penalty Program Instructio n ENGS 116 Lecture 12 23 Cache Performance CPU time = IC (CPIexecution + Mem accesses per instruction Miss rate Miss penalty) Clock cycle time Misses per instruction = Memory accesses per instruction Miss rate CPU time = IC (CPIexecution + Misses per instruction Miss penalty) Clock cycle time These formulas are conceptual only. Modern day out-of-order processors hide much latency though parallelism. ENGS 116 Lecture 12 24 Summary of Cache Basics • Associativity • Block size (cache line size) • Write Back/Write Through, write buffers, dirty bits • AMAT as a basic performance measure • Larger block size decreases miss rate but can increase miss penalty • Can increase bandwidth of main memory to transfer cache blocks more efficiently • Memory system can have significant impact on program execution time, memory stalls can be over 100 cycles • Faster processors => memory stalls more costly