Survey
* Your assessment is very important for improving the work of artificial intelligence, which forms the content of this project
Molecular graphics wikipedia , lookup
Spatial anti-aliasing wikipedia , lookup
General-purpose computing on graphics processing units wikipedia , lookup
Hold-And-Modify wikipedia , lookup
Tektronix 4010 wikipedia , lookup
MOS Technology VIC-II wikipedia , lookup
Graphics processing unit wikipedia , lookup
BSAVE (bitmap format) wikipedia , lookup
Waveform graphics wikipedia , lookup
Apple II graphics wikipedia , lookup
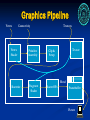
CSL 859: Advanced Computer Graphics Dept of Computer Sc. & Engg. IIT Delhi Adrianne Demo Skin shader 1,400 instructions per pixel 15 render passes Five bump maps Physically-based lighting with sub-surface scattering Three skin layers with different scattering properties. Complex anisotropic hair shader Real geometry GPU-accelerated character skinning Blendshapes Sculpt deformers Skeletal-driven bump maps Graphics Pipeline Geometry Transform Light Clip Setup Blend Rasterize Texture Z-test Framebuffer Picture Graphics Pipeline Vertex Connectivity Vertex Shader Rasterize Primitive Assembly Fragment Shader Textures Texture Clip & Setup Blend Raster OPs Framebuffer Picture Bottlenecks Too many operations Parallelize Too many memory accesses Parallelize SCREEN TILE XBAR GEOMETRY OPERATIONS FRAGMENT OPERATIONS SCREEN TILE SCREEN TILE Parallelization Distribute computation to processors Work allocation Distribute texture to memory banks Tile Screen-pixels into memory banks Do all processors have access to all memory Distribute access/Replicate data Sorting Taxonomy Sort first Sort middle Allocate to processor, which is responsible for only a given area of the screen Optimally perform geometry ops and then distribute to the responsible processor Sort last No-screen subdivision. Optimally perform geometry and fragment ops and then compose results Memory Considerations Highly pipelined Memory bandwidth How many accesses per second? Latency Guard against stalls Latency hiding buffers Larger memory atoms e.g., 32 byte atoms Graphics Architecture: A Brief History Evans & Sutherland Ikonas UNC Chapel Hill Silicon Graphics (Mushroom: Smart VGA controllers) nVIDIA, AMD IKONAS 32 bit data, 24 bit address bus backbone Host interface = address registers to access anything on the bus. Frame buffer resolution and timing could be set via control registers. Graphics processor Everything memory mapped (micro)Programmable 32 bit integer ALU and 16x16 bit integer multiplier Address counters, Loop counters and 64 bit instruction word. Plug-in boards 16 bit graphics processor with 16 pixel-at-once parallel write microprogrammed 16x16 bit matrix multiplier microprogrammed floating point matrix multiplier hardware Z-buffer real-time alpha-blend hardware for two RGB images real-time RGB video frame grabber IKONAS 1981 Pixel-planes 5 1989 2 GPs per board 1 128x128 array per board Upto 32 GPs, i860, and upto 8 Renderers Pixel-planes 5 Renderer 1 board had 64 mini-chips: Each with 2 columns of 128 pixel processors (w/memory) Renderer 64 chips of 256 pixel processing elements (PE Each PE has 208 bits of memory, the chip contains a Quadratic expression evaluator (QEE) Ax+By+C+Dx2+Exy+Fy2 simultaneously at each pixel Basic Algorithm Host app transmits model database and new frame requests to MGP Screen divided statically into bins of 128x128 pixels MGP broadcasts database commands to all GPs. GPs generate Renderer commands for each prim MGP allocates Renderers to screen regions Commands inserted into appropriate bins GPs send the bins Round-robin The Renderers send computed pixels to the frame buffer. SGI RealityEngine Kurt Akely 1993: The implementation is near-massively parallel, employing 353 independent processors in its fullest configuration, resulting in a measured fill rate of over 240 million antialiased, texture mapped pixels per second. Rendering performance exceeds 1 million antialiased, texture mapped triangles per second. RealityEngine Architecture Input FIFO, Command Processor 6, 8, or 12 Geom Engines 1, 2, or 4 raster boards 5 Fragment Generators (Each has texture replica) 80 Image Engines 1280x1024 Framebuffer 256 bits/pixel RealityEngine Algorithm FIFO geometry distributed by CP to GEs GEs do geometry ops including setup GEs broadcast triangles to FG (Raster) Finely interleaved pixel assignment FG distribute fragments to IE IEs do raster ops IEs are the framebuffer RealityEngine GE FG IE PC Architecture (Upto 2.5Gbps biPCI Express directional per lane) MEM BUS North Bridge South Bridge PCI BUS FSB CPU ATA BUS nVIDIA 8800 Process Die Size Chip Package Basic Pipeline Config Memory Config System Interconnect FSAA 90nm 484mm² (681 million Transistors) 21.5mm x 22.5mm Flipchip 32 / 24 / 192 Textures / Pixels / Z 384-bit 6x 64-bit (GDDR – GDDR4) PCI Express x16 Multisampling, Supersampling, Coverage samp., Transparency 2x1/2x2/4x2 (On a 16x16 grid) Texture Textures Per Pass Texture Filtering Methods 128 Bilinear, Trilinear, 2-16x Anisotropic Texture Compression DXTC 1-5, 3Dc+ Fragment Processors 128x FP32 scalar MADD+MUL